While I have a moment before traveling to Costa Rica for the World History Association Conference, thought I’d share the slides from my presentation for the RUSA History Librarians Discussion Group. The theme of the panel was ‘Role/s of Humanities Librarians in the Digital Humanities’. It was awesome to talk with this group and all the better because it was alongside a friend and mentor of mine, Harriett Green. Thanks to Chella Vaidyanathan for the invite!
Issues worth reflecting on that cropped up during the Q & A:
- Charting the relationship between DH Librarian, Disciplinary Faculty, and Subject Librarian
- Negotiating text and data mining rights
- Supporting DH w/ varying levels of ‘technical’ skills
- DH needs assessment
- Methods for DH engagement on campus
Slides below with some choppy notes:




The Digital Humanities is a broad community of theory and practice.
Getting started doing this work can be a bit overwhelming.
Especially given that many of the methods and tools were created far afield
from the disciplines that are typically grouped under the Humanities.
A couple of years ago when I was thinking of getting started in DH while I working at the Library of Congress helping to grow a Digital Preservation program, I sought to focus my efforts by narrowing the tools and methods that I would learn to things that I knew would likely be useful to historians, given that my graduate training is in History.
This exploration turned into research and I subsequently presented and published on it. This gave me the confidence to do my own DH research, engage with faculty as a collaborator, and teach DH tools and methods.
So it was a process of narrowing from this big thing called DH to a more manageable and familiar thing. Im sure a similar approach could be taken on elsewhere.
Focusing on the things you think might be most useful given your disciplinary grounding, helps establish a foundation you can draw on to engage other disciplines where needed.

Despite well-considered plans to stay up to date and carry forth your research, it is still likely you will experience fairly regular discomfort under the barrage of new things to learn.
Even with a narrowed DH, there is always something new.
A new development, a new tool, a new debate, etc.
For me its helpful to look at the image on the slide everyday (it’s the wallpaper on my laptop)
It’s a reminder that being uncomfortable is a necessary precondition of growth.
A quick note on the value of being uncomfortable
Its tempting to focus effort on the areas of campus that seem most familiar for research partners or audiences for DH services, say humanities disciplines broadly defined.
This is great, but it runs the risk of missing out on working with people working in the Sciences, broadly defined.
It might seems like a stretch.
After all why would a computer scientist be interested in working on a humanities question?
A little more than a year ago at a colloquium that Harriett organized on DH at UIUC, I asked a couple of computer scientists that worked on a DH project what incentivized them to work on a DH project. They said because the data was different than the kind they would normally work with.
That was enough.

I find this statement partially verified in work Devin Higgins and I are doing with
Arend Hintze, a post doctoral research at the Adami Lab.
Adapting an algorithmic approach applied to twitter data and genetic
sequences to the public domain version of the Google Books Dataset.
A big part of his motivation to do this research with us seems to be motivated by working in another domain by virtue of access to different data – millions of books.
If I would have delved into second guessing Arend’s potential interest in
our question this work would have never happened.
Sometimes being willing to be uncomfortable turns up unexpected value.

I want to dispel the notion that DH in the library is a solitary endeavor.
When I talk about DH Im not just referring to this broad community of practice.
As a librarian I think about novel engagement of information and data literacy through DH pedagogy, about metadata, about data curation, about the possibilities of subject area engagement across the library. DH construed in this way, in this professional context, is a team based effort.
Its an activity and area of scholarship that thrives best when conducted in the context of a fellowship.

At MSU Libraries we have a Digital Humanities team, situated within the Digital Text Services unit.
Aside from broad responsibility for Digital Humanities, we collectively have liaison duties for Linguistics, Philosophy, American History, English Literature, American Literature, and Performing Arts
Outside of our unit, I have a quarter time appointment to our Data Curation unit, and my colleagues have appointments to our Digital Information Division, and Reference and Instruction.
Direct ties to subject areas combined with appointments to other parts of the library strengthens our ability to be effective with respect to collection preparation to support computational analysis, communicating principles of data curation, and staying informed about needs of the campus community.


At MSU we are fortunate to have high DH research activity
with curricular commitments to the value of DH.
Our College of Arts and Letters offers a graduate certificate and undergraduate specialization in DH.
We have an established DH center – Matrix: The Center for Digital Humanities & Social Sciences.
We have a Creativity Exploratory and Literary Cognition Lab.
The Libraries are themselves increasingly articulating their own DH research agenda.


I think about alignment methods as an external as well as internal activity.
Externally we do all of the above. Each activity has a distinct value.
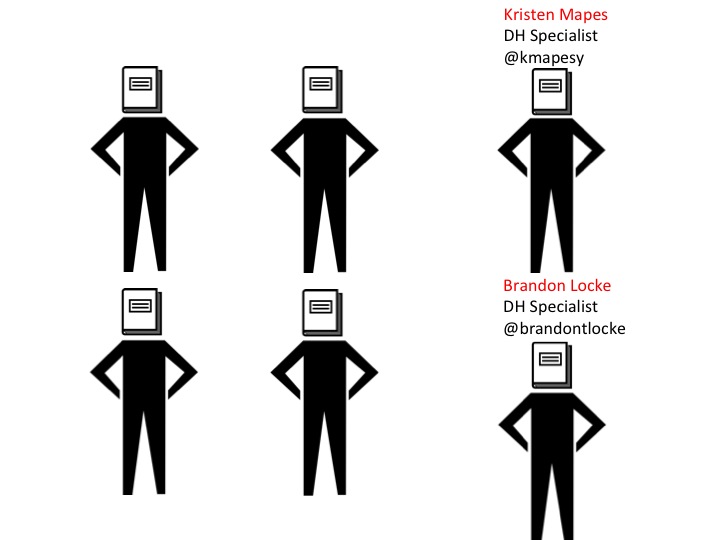
An exciting development in the past 2 months.
CAL and the History Department both hired their own DH Specialists.
Kristen Mapes in CAL and Brandon Locke for the History Department.
Kristen and Brandon are both coming out of LIS programs – like minds!
LIS solidarity I expect in coming months.

Re: internal alignment
We have this thing called the Digital Scholarship Collaborative.
A gathering of forces if you will within the library that serves to stimulate us intellectually and strengthen our ability to do good work.
Its composed of librarians dedicated to DH, our metadata librarian, a digital library programmer, our data librarian, and a number of other colleagues broadly vested in digital scholarship and the challenges and opportunities that it presents.

Other internal alignment is ongoing, and is prompted by
external research need that couldn’t have been thought up if we had tried.
Chicken or the egg is apt.
Im currently working with a faculty member in a humanities discipline, seeking to test an algorithmic approach to automatically identifying hedging language. So every time someone makes a hedge.
In order to take this work further we require access to Poultry Science journal literature en masse.
A text mining project.
This has prompted collaboration with the appropriate subject selector.
There is some convenience to this external pressure. It helps acquaint colleagues in the library to new use of the collections, and takes positive steps toward establishing precedent for stronger efforts to negotiate for text mining rights with the electronic content that we purchase.

Something of an elephant in the room re: needs assessment. We need to do it, and we will do it. That being said I do not think its appropriate to engage in this assessment without DH Specialist colleagues at MSU. It makes the most sense for us to collaborate and work toward getting information that helps us work together to advance Digital Humanities on campus.


My DH Pedagogy is greatly informed by the granularity of the Data Information Literacy Competencies.
There is a lot here, but really I think its tough to DH well without some degree of fluency in each of these areas.
Not possible to hit everything in a single session, but it’s a constant reminder to try and engage some of these things while teaching.

Lately this has meant an emphasis on METADATA.
I love METADATA.
And I try to get my students to love it too.

If they cant grasp its importance, then they cant reach their potential to DH well.

Typically I try to incentivize caring rather than scaring into caring.
Metadata is instrumental to data reuse and preservation but I don’t think that framing does a good job of making people see possibilities
So Ill take a moving image, or a movie
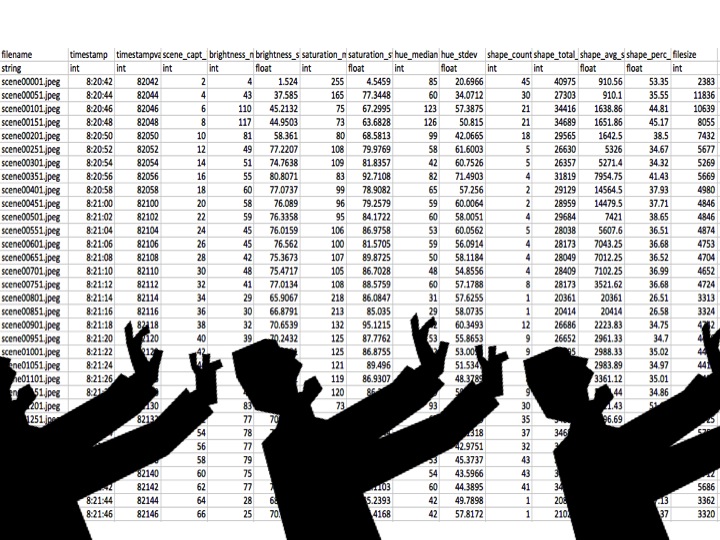
And Ill demonstrate, how quickly data can be generated that describes the data – or the movie in this case.
Lots of numbers.
In this case pixel intensities across every frame of a movie.
I try to get them to not freak out.

By showing them some of the interesting things they can do when they understand how that data can be harnessed to derive new insights about an object and a larger research question.

And at the end of this particular workshop, Im feeling happy if I can convert a couple of them to seeing the power and potential utility of metadata.
Not just a tool for preservation or description, but a body of information that can be used to visualize and analyze content in new ways.
So you could say that my DH pedagogy is heavily inflected by Data Information Literacy Competencies.

I see my collections work as going down two paths.
The first path is oriented toward finding, preparing, and making accessible digitized or born digital library collections in a manner that they are ready for various Digital Humanities research questions. It is often the case that the content management systems that we use to provide access to digitized content are an unnecessary and indeed an inhibiting factor. Too often an interfering layer of mediation where all that’s needed is access to data en masse.
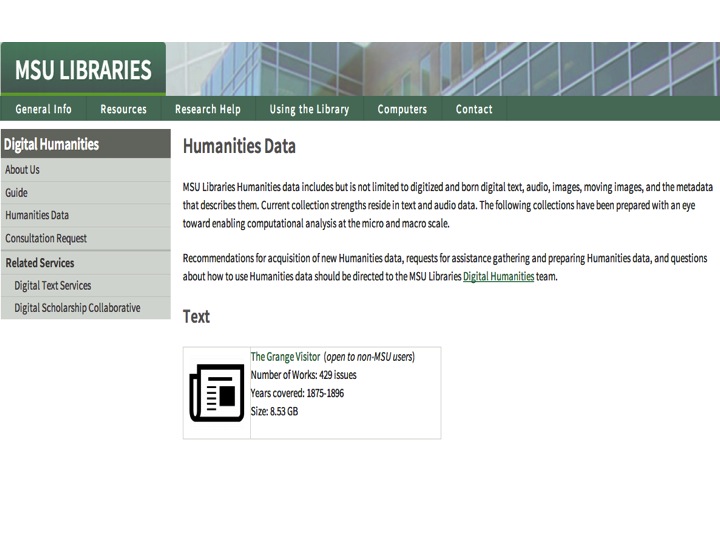
DH ready collections are referred to as ‘Humanities Data’ at MSU – mostly because they have been conditioned to support ease of computational analysis. In some cases this conditioning is fairly simple.
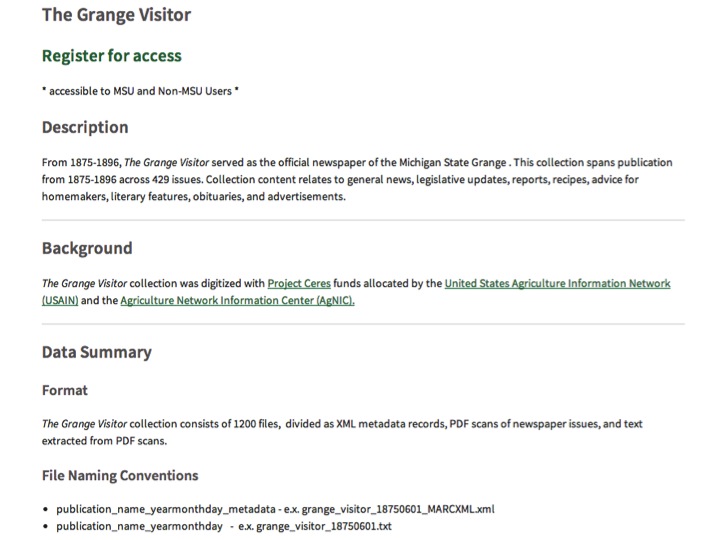
The test collection Im highlighting here is a historical newspaper. Ive extracted OCR from all the PDFs. Ive zipped the PDFs, OCR, and metadata into separate ZIP files, and Ive created a readme that describes all of the above with some background, file naming conventions, and data quality comments. Easy to grab this content and start hacking away. The plan is to extend this approach to other collections.

The second path is fairly traditional, and involves negotiation with various vendors for text and data mining rights. There is wide variation in these conversations, but commonality insofar as all vendors express interest given demonstrated demand for this type of use.


Just a quick note about research. I have a couple of different research plates spinning right now. Ill highlight one because it forms an indispensable component of how I see pedagogy, collections, and research fitting together.
We have at MSU the public domain portion of the Google Books Dataset.
About 3 million volumes of plain text.
My colleague Devin Higgins has developed an interface that allows MSU users to subset this collection with relative ease. This is invaluable collection development work. The collection is ripe for MSU DH coursework and research.
Devin and I, along with Arend Hintze have embarked on a research project with a portion of the Google Books Dataset to see what interesting things we might able to say about literary text, that is whether or not we can add to the conversation about its distinctive or not so distinctive characteristics at scale. Its a project of intellectual interest.
But importantly, it is also research that will serve to bolster our ability to promote use of this resource. It is one thing to point to a number of use cases, its another thing entirely to be able to say look at this great thing we’ve prepared for you, here are the research possibilities we’ve uncovered, lets have a conversation about how you or your students might realize their own insights working with this data.

1 comment