During graduate school I visited my fair share of archives. Living on funds dispensed from the FAFSA gods in combination with whatever part-time job I had, I often found myself hard-pressed to pony up money for photocopies. Somewhere along the line I got smarter and started using a point and shoot camera to gather as much primary source mana as possible. Since that time smart folks have written great posts geared toward helping people engaged in similar work. Robin Camille Davis has a nice post on using an iPhone, a ruler, and a couple stacks of books as an impromptu digitization station. Miriam Posner shows us how to batch process photos. The University of Illinois Libraries maintain a really useful guide on digital tools for archival research. Building on these foundations I am going to describe how you can generate plain text data from images of archival documents. With plain text data in hand you’ll be well provisioned for engaging a number of different Digital Humanities methods. The focus here is on extracting plain text data from images of print based archival content using optical character recognition(OCR). The result likely won’t be highly accurate, but I’d argue that “just good enough” is all you need to begin exploring your sources.
What You Need
– Macports – package management system, basically makes it easier for you to install software
– Tesseract – open source software used to perform optical character recognition
– Scanner / Camera – capture images in TIFF format
Installing Macports
– Download Macports for your version of OS X
– Double click .pkg file and follow instructions
Installing Tesseract (may or may not require installation of Xcode Command Line Tools)
– Open Terminal
– Enter the following command in Terminal: sudo port install tesseract-eng
This installation supports English language materials. To engage other languages, see documentation on additional language support.
Scanner / Camera Selection
Most scanners and copiers will provide an option to output to the TIFF format. If you are in an archive with one of those fancy overhead scanners with slot for USB drive, chances are TIFF is an option. Your life is charmed.
Camera selection is a bit trickier. Most DSLRs have a TIFF option. If you can’t spring for a DSLR some sleuthing seems to indicate that its possible to purchase phone apps that allow capture of images in TIFF format – fair warning – I haven’t tried the app.
Use Case – Generate Plain Text Data from a File using OCR
You visit an archive. Document of interest appears. It isn’t available anywhere else. You want to (1) capture an article from it (2) generate plain text data for potential use in a Digital Humanities project.

1. Scan or Photograph document, output to TIFF format, crop if needed

2. Open Terminal
3. In Terminal navigate to folder where file is located: e.g. cd Desktop/forum
4. Once in folder, enter the following command in Terminal: tesseract yourfilename.tiff yourfilename (Tesseract will generate a plain text file derived from the TIFF)
5. Compare the original image to the plain text file – not likely to be perfect match but probably just good enough
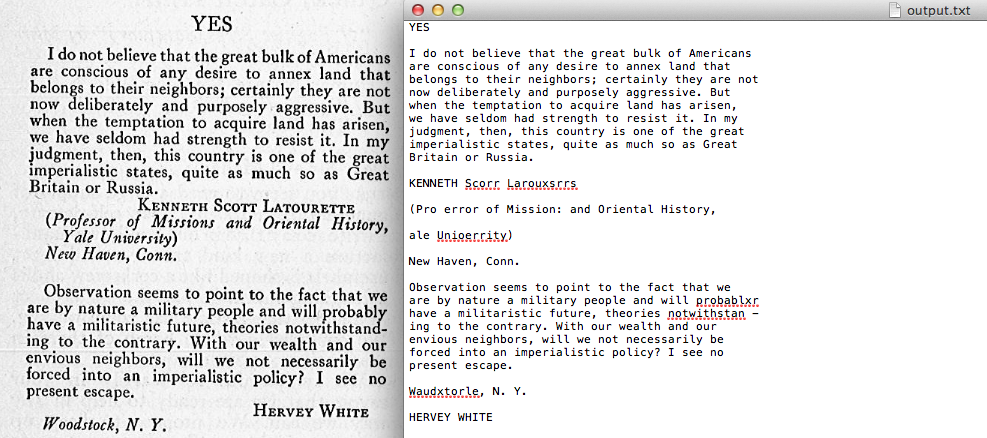
Use Case 2 – Generate Plain Text Data from Multiple Files using OCR
You visit an archive. Documents of interest appear. They aren’t available anywhere else. You want to (1) capture multiple documents (2) generate plain text data for potential use in a Digital Humanities project.
1. Scan or Photograph documents, output to TIFF format, crop if needed, create a folder to store these files
2. Open Terminal
3. In Terminal navigate to folder where files are located: e.g. cd Desktop/forum/1928_Forum
4. Once in folder, enter the following command in Terminal: for i in *.tiff; do tesseract $i yourfoldername_$i; done;
5. Review original images and plain text files.
There you go. “Just good enough” OCR for plain text data generation from archival resources. This is a low barrier approach that will generate data that is up to the task of enabling digitally inflected exploration of sources. Of course “just good enough” is a moving target. As your research project progresses and you need higher degrees of accuracy in the OCR consider the resources below.
Further Resources
Training Tesseract
Early Modern OCR Project
Automatic Evaluation of OCR Quality
2 comments